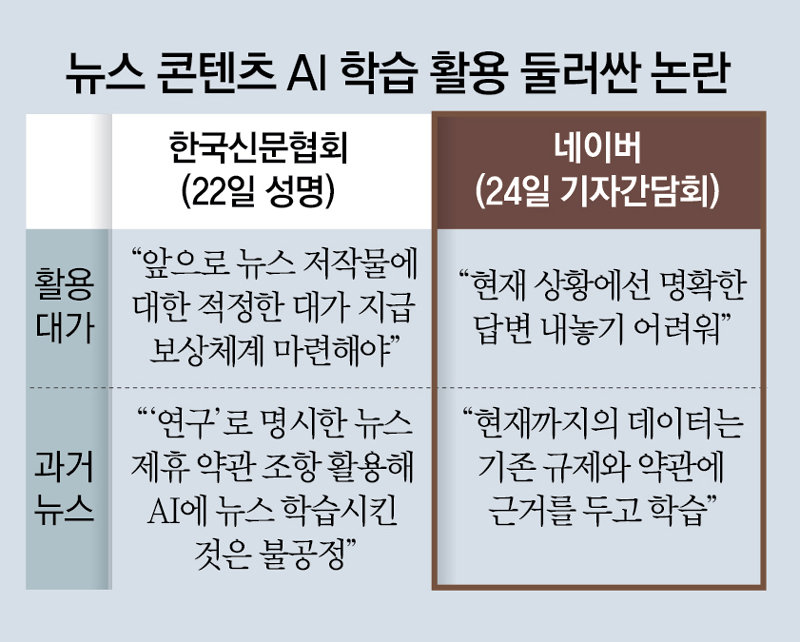
신문협회는 저작권 사용료 요구
최수연 대표 “기존학습, 약관에 근거
대가 지급 관련 논의 안하고 있어”
네이버가 한국어 기반 생성형 인공지능(AI)인 ‘하이퍼클로바X’를 공개했다. 오픈AI의 ‘챗GPT’와 마찬가지로 뉴스 등으로부터 방대한 데이터를 학습해 자연어를 이해할 수 있는 거대언어모델(LLM)을 기반으로 개발됐다. 뉴스 콘텐츠를 이용할 때 대가 지급 여부와 기준은 밝히지 않아 ‘저작권 침해’ 논란이 지속될 것으로 보인다.
최수연 네이버 대표는 24일 서울의 한 호텔에서 하이퍼클로바X를 소개하며 “영업수익의 22%를 연구개발(R&D)에 꾸준히 투자했고, 이를 토대로 기술을 고도화하고 양질의 데이터를 확보했다”고 밝혔다. 하이퍼클로바X는 네이버가 2021년 세계에서 세 번째로 공개한 LLM ‘하이퍼클로바’의 업그레이드 버전으로 한국어에 최적화한 LLM이다. 네이버에 따르면 오픈AI의 GPT-3.5와 비교해 한국어를 6500배 이상 학습했다.
네이버는 이날 하이퍼클로바X를 기반으로 한 대화형 AI 서비스 ‘클로바X’와 생성형 AI 기술이 적용된 검색 서비스 ‘큐(CUE:)’도 선보였다. 시범 서비스를 시작한 클로바X는 대화하는 방식으로 이용자에게 요약, 추론, 번역 등 다양한 답변을 제공한다. 최 대표는 “하이퍼클로바X는 한국어 표현을 포함해 한국 사회의 제도와 법 등을 가장 잘 이해하는 생성형 AI”라며 해외 빅테크의 서비스와 비교해도 경쟁력이 있다는 점을 강조했다.
현재 LLM의 학습 과정에서 네이버가 얼마나 많은 양의 뉴스를 활용했는지도 공개하지 않았다. 최 대표는 “현재까지 네이버 AI가 학습한 데이터는 기존 규제와 약관에 근거를 두고 학습했기 때문에 별도의 대가 지급과 관련해 논의하고 있진 않다”고 설명했다. 앞서 신문협회는 “뉴스 콘텐츠를 ‘연구’ 목적으로 활용할 수 있도록 한 약관 조항에 따라 AI 학습에 활용한 것이라면 언론사들이 알지 못한 내용인 만큼 불공정하다”고 지적했다.
4차 산업혁명 시대 >
구독

-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개
-
- 추천해요
- 개



댓글 0