
핫 칩스 2024는 1989년부터 미국 실리콘 밸리 일대에서 개최되는 마이크로프로세서 및 관련 직접회로 산업 콘퍼런스로, 칩 설계자와 시스템 엔지니어, 국가 연구소 및 학계에서 약 500여 명 이상이 참석해 임베디드 및 FPGA, 양자 컴퓨팅, 나노 구조, 무선 칩, 네트워크 및 보안, 고급 패키징 기술 등의 주제를 논의한다.
올해 콘퍼런스는 퀄컴, AMD, 인텔, 삼성전자, 엔비디아 등 주요 반도체 기업은 물론 퓨리오사AI, 삼바노바(SambaNova), 엘리얀(eliyan), 플로 컴퓨팅(FLOW computing), 암페어 컴퓨팅 등 업계에서 주목받는 스타트업들도 대거 참가했다. 아울러 한국과학기술원, 울산과학기술원에서도 뉴럴 칩, 에너지 효율 AI 가속기, 자율주행용 시스템온칩(SoC) 등의 논문을 발표했다.
핫 칩스 2024, 글로벌 기업과 스타트업의 AI 각축전
핫 칩스는 대중 행사가 아닌 반도체 학술 행사지만, 대규모 자본 및 개발 과정이 수반되는 반도체 개발 특성상 빅테크 기업이 주로 참여한다. 엔비디아는 칩 설계용 AI와 LLM 지원, 차세대 냉각 시스템, 생성 AI 및 가속 컴퓨팅 지원을 위한 엔비디아 블랙웰 플랫폼을 발표했고, 인텔은 AI PC용 루나레이크 및 서버용 인텔 제온 6, 가우디 3 AI 가속기, 칩렛 기술 등을 주로 소개했다.

퓨리오사AI의 발표는 AI 프로세서를 주제로 하는 8월 26일 오후에 진행됐다. 앞서 엔비디아 블랙웰, 삼바노바 SN40L RDU, 인텔 가우디 3, AMD 인스팅트 MI300X, 브로드컴 ASIC에 대한 주요 발표가 진행됐고, 퓨리오사AI는 이날 마지막으로 발표했다. 주요 기업들의 발표가 이어진 뒤 등장하는 스타트업의 AI 가속기인 만큼 학계 및 업계 관계자들의 시선이 집중된 참이었다.
백준호 퓨리오사AI 최고경영자는 “AI 모델은 우리 일상 속으로 스며들고 있으며, 추론은 물이나 전기 같은 사회 인프라가 될 것이다. 우리는 개인 맞춤화하고, 효율적이면서 고성능의 AI 반도체를 구축하기 위해 이 칩을 만들었다”라면서, “21년까지 진행한 초기 설계는 당시 최고 모델에 맞췄으나, 다섯 배 이상 더 큰 GPT3의 등장으로 우리는 디자인에 큰 변화를 줬다. 스타트업이 이런 규모의 개발을 하는데 따른 위험이 컸지만, 미래 잠재력을 믿고, 사람들이 유능한 AI 모델을 선호할 것이라고 믿으며 개발을 시작했다”라고 말했다.

백준호 대표는 “레니게이드는 현재와 미래의 가장 발전된 AI 모델을 처리하기 위한 추론 장치다. 512테라플롭스의 컴퓨팅 성능과 BF16 및 INT4 처리 지원, 48GB 고대역폭 메모리와 256MB SRAM을 갖췄다. 메모리는 전체 성능에 많은 영향을 미치는 것을 감안해 의도적으로 더 높은 성능과 용량으로 설계했다”라고 설명했다.
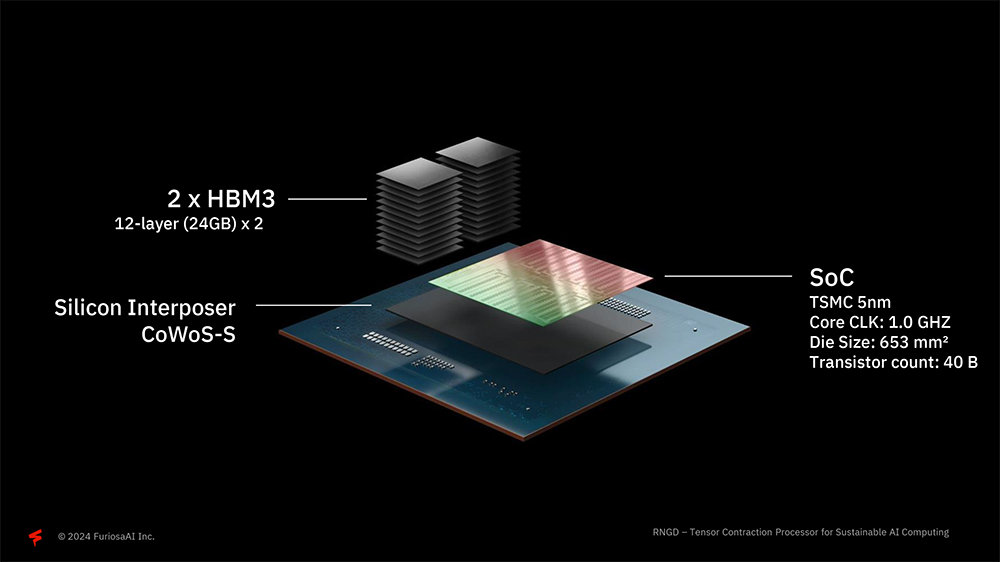
퓨리오사AI가 의도한 열설계전력(TDP)은 150W다. 열설계전력이 낮으면 그만큼 발열도 적기 때문에 밀집도를 올릴 수 있고, 데이터 서버 냉각 비용 등을 절감할 수 있다. 레니게이드는 쿨링팬이 없어 공랭식 기반 데이터 센터에 적합하다. 또한 TSMC 5nm 공정을 활용해 가격대 성능비를 끌어올리고, SoC 다이 하나에 약 400억 개의 트랜지스터를 구축했다. 여기에 HBM 모듈과 SoC를 단일 실리콘으로 통합하는 CoWoS-S(칩온웨이퍼-온서브스트레이트)를 사용해 내부 데이터 통신 속도를 끌어올렸다.

AI 가속기의 성능을 변별력 있게 시험하는 MLPerf 결과를 토대로 RNGD의 성능과 엔비디아 L40S, 인텔 가우디 2, 구글 TPU v5e를 비교했다. 이때 RNGD는 GPT-J 6B 모델 벤치마크 시나리오에서 FP8 기준 초당 11.5 쿼리를 처리했으며 소비전력은 185W였다. 반면 엔비디아 L40S는 성능은 초당 12.3 쿼리로 소폭 높았지만, 소비전력은 두 배에 가까운 320W다. 와트당 성능으로 비교하면 RNGD가 L40S 대비 60% 앞선다. 인텔 가우디 2와 구글 TPU의 소비전력 정보가 없지만, 실용 수준에서는 확실히 높은 효율성이다.
백준호 대표는 “AI 영향력은 하드웨어 성능에서만 비롯되는 건 아니다. 하드웨어 효율성과 소프트웨어 효율성, 알고리즘 등이 조합되고, 모델의 광범위한 기술도 고려해야 한다. 우리는 양자화를 위한 아키텍처 소프트웨어 자동화를 매일 개선하고 있고, 모든 계층에서 효율성을 혁신하고 통합하고 있다”라고 덧붙였다.
텐서 자체를 처리··· 데이터 재사용으로 효율 높여
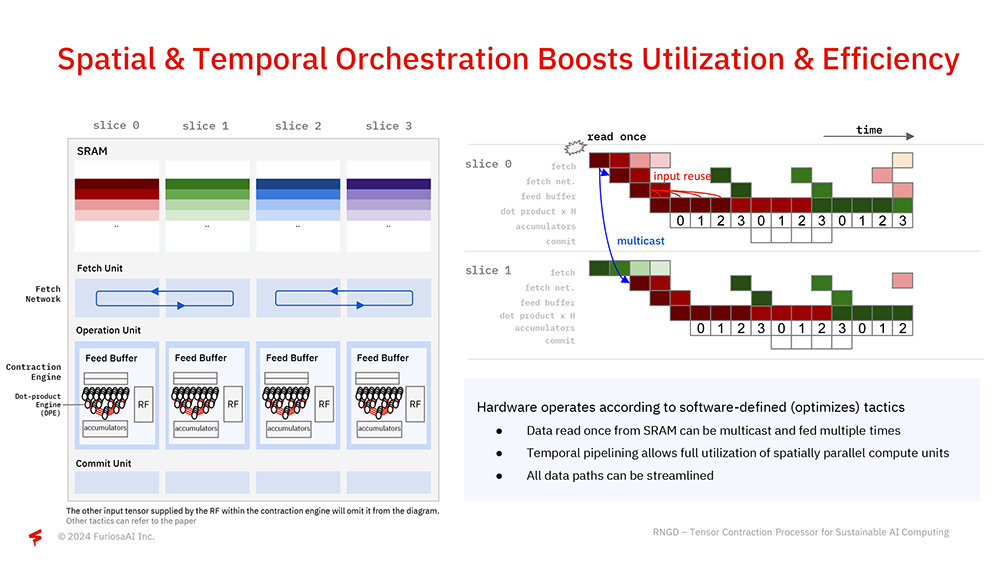
RNGD의 구조적 배경에는 텐서 축약(Tensor Contraction)이 있다. 백준호 대표는 “AI 아키텍처는 효율뿐만 아니라 자체적으로 진화하도록 적응성과 프로그래밍이 되어야 한다. 하드웨어 유연성 없이 특정 기능에만 최적화하면 전반적인 효율성 경쟁에서 뒤처진다. 우리는 7년 간 신경망 처리의 핵심인 텐서 처리를 개선하는 것에 초점을 맞춰왔다”라며 설명을 시작했다.
텐서 축약은 행렬 곱셈(Matrix Multiplication)을 더 높은 차원으로 계산하는 방식이다. 현재 일반적인 AI 가속기는 데이터를 여러 차원으로 나눠서 담는 텐서로 만들어 처리하고, 이를 축약해 처리한다. 축약 과정에서 행렬 곱셈으로 처리하는 것은 텐서의 병렬성과 데이터 지역성을 살리지 못하고, 또 데이터를 재사용하는 범위도 제한된다. RNGD는 텐서축약 자체를 처리하는 방식으로 데이터를 대규모로 병렬 처리하고, 데이터도 재사용해 효율성을 끌어올린다.
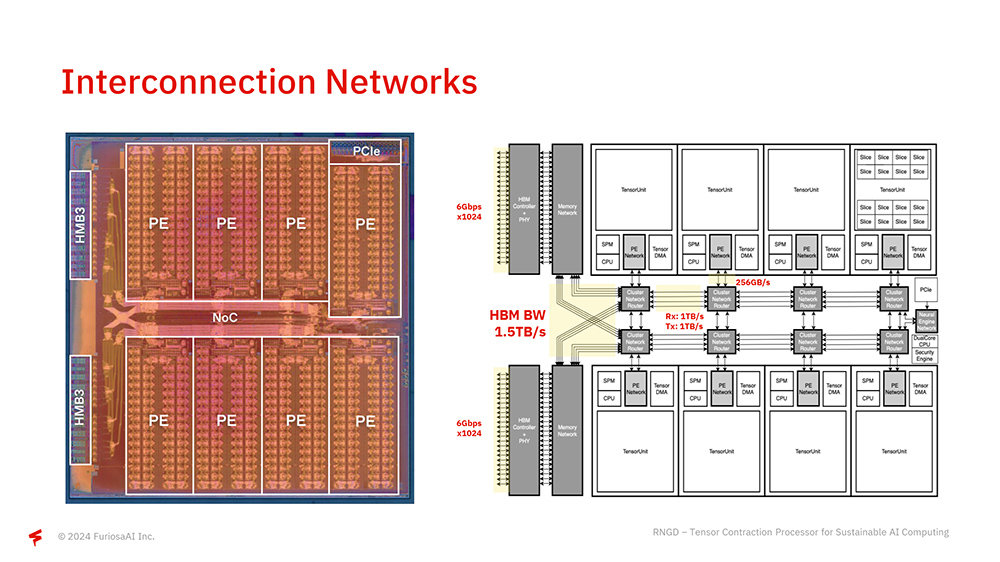
텐서 축약 프로세서의 구체적인 내부 구조도도 소개됐다. RNGD는 내부에 8개의 프로세싱 엘리멘트(PE)로 데이터를 처리한다. 각 요소는 칩 내 네트워크(NoC)로 연결돼 있으며, 각 PE가 1.5TB 대역폭의 HBM으로 통신한다. 호스트 인터페이스는 PCIe 5세대 16레인이 사용되며, 이를 통해 단일 서버에 최대 20개의 RNGD 칩을 탑재할 수 있다.
하드웨어뿐만 아니라 소프트웨어 지원에도 큰 비중
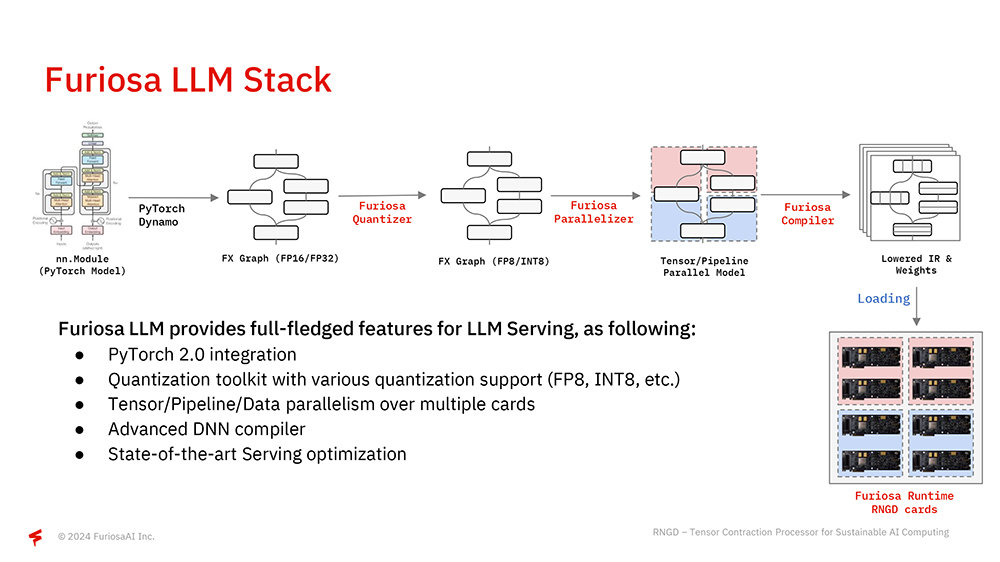
백준호 대표는 “모든 자사 NPU의 구성 요소는 수직 통합되고 최적화됐다. 이미지는 새로운 모델에 대해 고성능을 제공하기 위한 소프트웨어 스택 개요다. 현재 우리는 파이토치 2.0 지원에 중점을 두며, 첫 단계에서 낮은 정밀도로 모델을 양자화한다. 그다음 여러 개의 PE를 대상으로 하는 파이프라인 또는 텐서 수준의 병렬 처리 등의 전략을 여러 칩에 적용한다”라고 설명했다
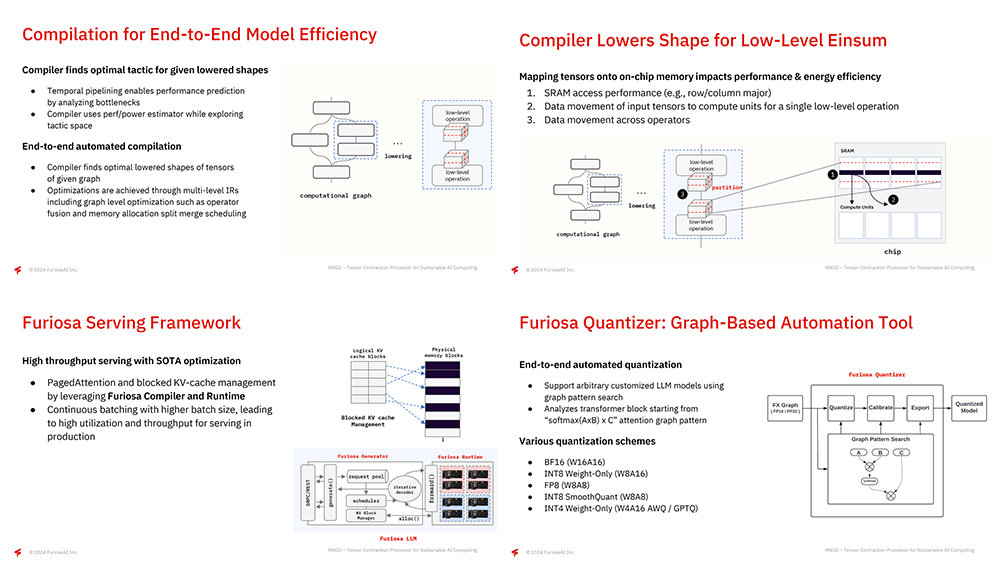
아울러 엔드 투 엔드 모델 최적화와 서비스 프레임워크의 중요성도 강조했다. 퓨리오사AI는 다양한 AI 모델이 문제없이 작동하도록 컴파일러 및 소스 코드의 데이터 내부 구조인 IR(Intermediate Representation) 단위에서 최적화하고, 메모리 레이아웃을 최적화해 접근 성능은 높이고, 이동은 최소화한다. 또 연산자 융합, 텐서 분할 등 다양한 최적화 기법을 적용한다.
서비스 프레임워크 측면에서 퓨리오사 컴파일러와 런타임은 가상 메모리 및 페이징 구조를 참고로 딥러닝 어텐션을 계산할 때 효율적인 페이지드 어텐션, 토큰 계산 시 반복 계산되는 값을 재사용하는 KV 캐시 등에 영향을 미친다. 또한 앤드 투 앤드 단위에서 자동으로 양자화를 진행하며, 트랜스포머 블록의 어텐션 그래프 패턴을 분석해 양자화에 적합한 부분을 찾아낸다. BF16, INT8, FP8, INT4 등 다양한 수치상 설계(numerical scheme) 지원 및 AWG(Adaptive Weight Quantization), GPTQ(GPT Quantization) 등의 최신 양자화 기법도 지원한다.
닻 올린 퓨리오사AI, 2세대 반도체로 시험길에 오르다
발표 말미에 백준호 퓨리오사AI 대표는 “퓨리오사AI 소프트웨어는 전적으로 역언어(Inverse Language)로 작성되었으며, 레지스터 트랜스퍼 레벨 개발을 위해 언어 학자 수준의 언어를 쓰고 있다. 이것은 스케줄에 맞춰 생산되는 칩 중에서는 가장 독창적인 것이라 생각한다”라면서, “퓨리오사AI는 백여 명 이상의 엔지니어를 보유한 스타트업이다. 우리는 항상 진보된 개발 방법론을 찾기 위해 노력하고, 최신의 기술과 언어를 지원하고자 최선을 다할 것”이라고 말했다.

핫 칩스 2024를 계기로 퓨리오사AI의 2세대 반도체 RNGD가 세계 무대에 공식 등판했다. 국내 AI 가속기로는 놀라운 성과고, 글로벌 반도체 시장 전체를 포함해도 주목할만한 행보다. 이번 발표를 앞두고 퓨리오사AI는 2세대 반도체의 성공적인 시장 데뷔를 위해 꾸준히 물밑작업을 해왔다.
글로벌 반도체 성능 지표라 할 수 있는 MLPerf의 LLM 항목에 대한 테스트는 지금도 작업이 한창이고, 또 광주광역시에 위치한 인공지능산업융합사업단(AICA)의 ‘AI 반도체 시험검증 환경조성’ 사업(과학기술정보통신부, 광주광역시, 정보통신산업진흥원)을 통한 AI반도체 시험장비 활용 지원 프로그램의 도움을 받아 RNGD를 PCI-SIG의 통합 리스트에 등재하기도 했다.
RNGD는 오는 9월 초부터 공식 판매를 시작한다. 우선은 계약된 기업 대상으로 판매를 시작하고, 연말쯤에는 전체 시장을 대상으로 제품을 공급한다. 특히 엔비디아 등 대규모 AI 반도체 기업이 부족한 부분을 집중 공략하고, 소프트웨어를 직접 지원하는 방식으로 시장 경쟁력 확보에 나선다. 퓨리오사AI의 항해는 이제부터 시작이다.
IT동아 남시현 기자 (sh@itdonga.com)
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0