“AI가 기사-콘텐츠 도둑질”… WSJ, 오픈AI에 소송 검토
- 동아일보
-
입력 2023년 4월 20일 03시 00분
공유하기
글자크기 설정
“챗GPT 학습에 콘텐츠 이용하려면 대가 지불해야”
美 언론-SNS, 빅테크에 요구
기사-데이터 무단사용 제동
하루 5700만 명이 찾는 미국 소셜미디어 레딧이 빅테크 인공지능(AI)의 자사 콘텐츠 무료 활용에 제동을 걸고 “비용을 지불하라”고 요구하고 나섰다. 빅테크가 언론사 기사, 소셜미디어 대화 내용 등을 AI 학습에 무단으로 사용하는 행위에 제동을 건 것이다.18일(현지 시간) 레딧은 자사 사이트에 있는 대화 데이터를 상업적으로 사용하려면 비용을 지불해야 한다고 밝혔다. 구글이나 마이크로소프트(MS), 오픈AI가 생성형 AI 정확도를 높이기 위해 레딧 콘텐츠를 무료로 가져다 쓰는 일을 막겠다는 취지다. 레딧의 거대한 대화 데이터는 빅테크가 경쟁적으로 개발 중인 대규모언어모델(LLM)의 ‘과외 선생님’ 역할을 해왔다.
스티브 허프먼 레딧 최고경영자(CEO)는 뉴욕타임스(NYT)와의 인터뷰에서 “레딧을 긁어 가치를 창출하면서 이를 사용자에게 돌려주지 않는 것이 문제”라며 “대가를 지불하게 하는 것이 공정하다”고 밝혔다. 소셜미디어뿐 아니라 NYT를 비롯해 미국과 캐나다 언론사 2000여 곳이 소속된 뉴스미디어연합(NMA)도 집단 대응을 고심 중이다.
AI ‘공짜 학습’에 제동
챗GPT 학습에 언론사 기사 무단사용
WSJ “적절한 라이선스 받아야”
트위터-레딧 “데이터 보호” API 유료화
챗GPT 학습에 언론사 기사 무단사용
WSJ “적절한 라이선스 받아야”
트위터-레딧 “데이터 보호” API 유료화

“사람이 노력하고 투자해 만든 콘텐츠가 (AI 학습에) 끊임없이 무단으로 사용되고 있다.”
뉴스미디어연합(NMA)의 대니얼 코피 부회장은 최근 월스트리트저널(WSJ)에 이같이 말하며 AI 학습에 뉴스 콘텐츠가 어느 정도 활용되고 있는지 조사 중이라고 밝혔다. NMA는 뉴욕타임스(NYT) 등 미국 캐나다의 2000여 개 언론사가 소속된 미디어 단체다.
챗GPT와 같은 생성형 AI를 개발하는 데 가장 중요한 두 요소로 학습에 필요한 엄청난 양의 데이터, 이를 소화할 만한 뛰어난 컴퓨팅 파워가 꼽힌다. 문제는 ‘엄청난 양의 데이터’가 수많은 사람들이 창조한 콘텐츠라는 점이다. 언론사 기사, 소셜미디어 대화와 개인 콘텐츠, 학술 논문, 프로그램 개발 코드 등이 대표적이다. 온라인에 공개된 콘텐츠라도 허가 없이 상업적으로 활용하는 것이 적절한지가 AI 학습 저작권 논란의 핵심이다.
● ‘뉴스 어디서’ 질문에 언론사 줄줄
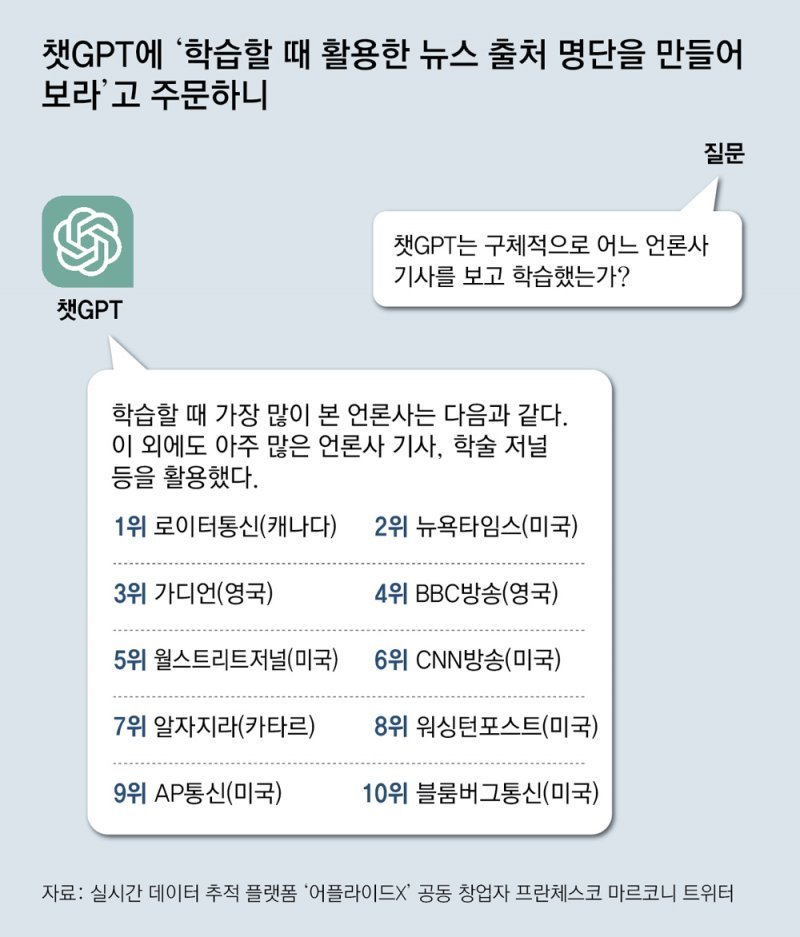
MS의 빙AI나 구글 바드가 사용자 질문에 답할 때 언론사 기사 내용을 요약해 알려주고, 링크도 제대로 걸지 않는 점에 대해서도 미 언론사들은 문제를 제기하고 있다.
언론사뿐 아니라 소셜미디어도 ‘우리 콘텐츠로 빅테크가 돈을 버는 것은 불공평하며 저작권 침해’라며 반기를 들고 있다. 일론 머스크 트위터 최고경영자(CEO)는 지난해 12월 “놀랄 일도 아니지만 방금 오픈AI가 AI 학습을 위해 트위터 데이터베이스에 액세스할 수 있다는 것을 알게 됐다”며 “나는 이를 막을 것”이라고 밝혔다.
트위터는 결국 올 2월 데이터베이스에 접근할 수 있는 응용프로그램인터페이스(API)를 유료화했다. 레딧도 2008년부터 무료로 운영하던 API 공개 정책을 18일 ‘상업적으로 이용 시 유료’ 조건을 달아 트위터의 뒤를 이었다. NYT는 “레딧의 유료화 정책은 AI 학습과 관련한 소셜미디어의 움직임에 있어 중요한 사례”라고 평했다.
● “개발 코드 무단 사용” 소송전도
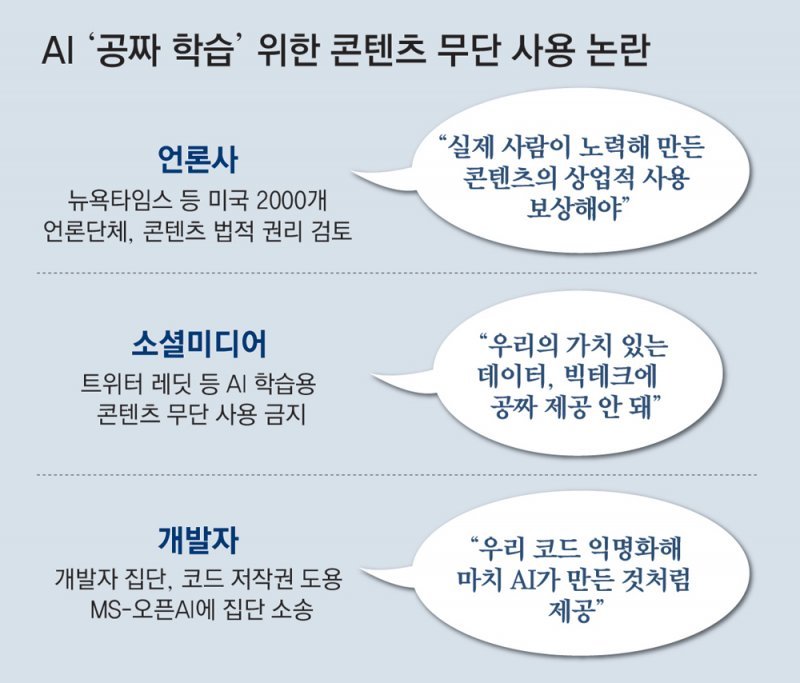
개발 코드를 쉽게 만들어 주는 AI인 MS의 코파일럿, 오픈AI의 코덱스가 깃허브 등에 올라와 있는 코드로 학습하고, 이를 익명화해 AI 답변으로 제공하고 있어 저작권이 침해됐다는 것이다. 이들은 소장에서 “우리가 개발 코드를 공유할 때, 저작자 이름이나 라이선스를 명기하도록 해왔다”며 “하지만 AI는 오픈 소스 조건을 무시하고 무작위로 학습한 뒤 이를 배포하고 있다”고 밝혔다.
콘텐츠 무단 사용 논란에 샘 올트먼 오픈AI CEO는 미 언론 인터뷰에서 “필요한 경우 콘텐츠 거래를 통해 AI를 학습시켰다. 특정 영역의 고품질 데이터에는 기꺼이 비용을 지불할 것”이라고 밝혔다. 하지만 언론사, 소셜미디어, 개발자, 아티스트, 이미지 업체 등이 모두 반발하고 있어 논란과 소송전은 지속될 것으로 전망된다. 개인 콘텐츠에 담긴 사적인 정보가 답변에 노출된 사례도 나오자 이탈리아는 임시로 챗GPT 사용을 중단시킨 상태다.
WSJ는 “(대용량의 언어 데이터를 학습할 수 있는) AI 기술이 산업적인 규모의 지식재산권 도용을 가능하게 하고 있다”라고 우려했다.
© dongA.com All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
트렌드뉴스
-
1
“스페이스X 기대감에 200% 급등”…블룸버그, 한국 증권주 ‘우회 투자’ 부각
-
2
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
3
美대법 “의회 넘어선 상호관세 위법”…트럼프 통상전략 뿌리째 흔들려
-
4
“심장 몸 밖으로 나온 태아 살렸다” 생존 확률 1% 기적
-
5
야상 입은 이정현 “당보다 지지율 낮은데 또 나오려 해”…판갈이 공천 예고
-
6
17년 망명 끝에, 부모 원수 내쫓고 집권[지금, 이 사람]
-
7
스벅 통입점 건물도 내놨다…하정우, 종로-송파 2채 265억에 판다
-
8
대미투자 약속한 韓, ‘트럼프 상호관세 위법’으로 불확실성 휩싸여
-
9
주한미군 전투기 한밤 서해 출격…中 맞불 대치
-
10
“호랑이 뼈로 사골 끓여 팔려했다”…베트남서 사체 2구 1억에 사들여
-
1
“尹 무죄추정 해야”…장동혁, ‘절윤’ 대신 ‘비호’ 나섰다
-
2
尹 “계엄은 구국 결단…국민에 좌절·고난 겪게해 깊이 사과”
-
3
“재판소원, 4심제 운영 우려는 잘못… 38년전 도입 반대한 내 의견 틀렸다”
-
4
한동훈 “장동혁은 ‘尹 숙주’…못 끊어내면 보수 죽는다”
-
5
유시민 “李공소취소 모임, 미친 짓”에 친명계 “선 넘지마라”
-
6
尹 ‘입틀막’ 카이스트서…李, 졸업생과 하이파이브-셀카
-
7
“尹어게인 공멸”에도 장동혁 입장 발표 미뤄… 국힘 내분 격화
-
8
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
9
“윗집 베란다에 생선 주렁주렁”…악취 항의했더니 욕설
-
10
[사설]“12·3은 내란” 세 재판부의 일치된 판결… 더 무슨 말이 필요한가
트렌드뉴스
-
1
“스페이스X 기대감에 200% 급등”…블룸버그, 한국 증권주 ‘우회 투자’ 부각
-
2
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
3
美대법 “의회 넘어선 상호관세 위법”…트럼프 통상전략 뿌리째 흔들려
-
4
“심장 몸 밖으로 나온 태아 살렸다” 생존 확률 1% 기적
-
5
야상 입은 이정현 “당보다 지지율 낮은데 또 나오려 해”…판갈이 공천 예고
-
6
17년 망명 끝에, 부모 원수 내쫓고 집권[지금, 이 사람]
-
7
스벅 통입점 건물도 내놨다…하정우, 종로-송파 2채 265억에 판다
-
8
대미투자 약속한 韓, ‘트럼프 상호관세 위법’으로 불확실성 휩싸여
-
9
주한미군 전투기 한밤 서해 출격…中 맞불 대치
-
10
“호랑이 뼈로 사골 끓여 팔려했다”…베트남서 사체 2구 1억에 사들여
-
1
“尹 무죄추정 해야”…장동혁, ‘절윤’ 대신 ‘비호’ 나섰다
-
2
尹 “계엄은 구국 결단…국민에 좌절·고난 겪게해 깊이 사과”
-
3
“재판소원, 4심제 운영 우려는 잘못… 38년전 도입 반대한 내 의견 틀렸다”
-
4
한동훈 “장동혁은 ‘尹 숙주’…못 끊어내면 보수 죽는다”
-
5
유시민 “李공소취소 모임, 미친 짓”에 친명계 “선 넘지마라”
-
6
尹 ‘입틀막’ 카이스트서…李, 졸업생과 하이파이브-셀카
-
7
“尹어게인 공멸”에도 장동혁 입장 발표 미뤄… 국힘 내분 격화
-
8
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
9
“윗집 베란다에 생선 주렁주렁”…악취 항의했더니 욕설
-
10
[사설]“12·3은 내란” 세 재판부의 일치된 판결… 더 무슨 말이 필요한가
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개


![[동아광장/이은주]AI 기본법 최초 시행, 신뢰성 고민이 먼저다](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News2/133392669.1.thumb.png)


댓글 0