요즘 IT의 가장 큰 이야깃거리는 ‘챗GPT’죠. 과학소설작가 테드 창(Ted Chiang)도 지난주에 주간지 ‘뉴요커’에 챗GPT를 설명하는 글을 기고했는데요, 컴퓨터 과학을 전공한 작가답게 ‘대규모 언어 모델(large language model)’의 한계와 단점에 대해 이야기합니다.
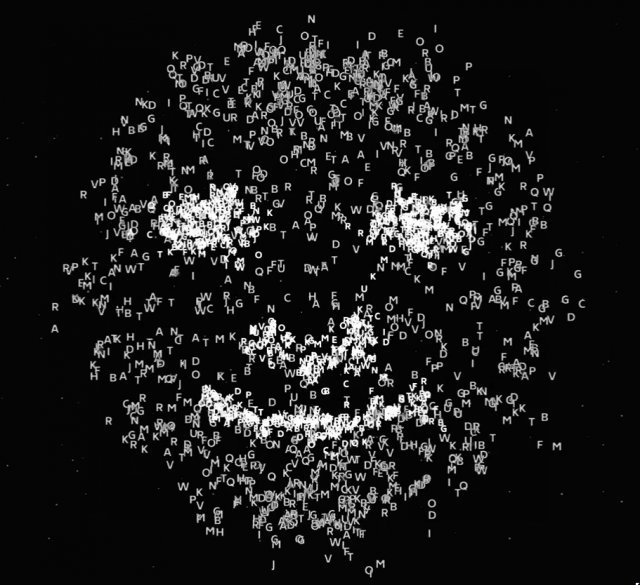
저는 사진기자로서 직업병 때문인지, 인공지능을 이미지 압축방식인 JPG로 설명해서 관심을 가졌고 덕분에 AI에 대해 조금, 아주 조금이나마 이해할 수 있게 됐습니다.
물론 그래도 어렵습니다만…내용을 요약해 독자분들과 공유하고자 합니다. 제가 이해한대로 의역하고 구성한 부분이 있어 원문과는 좀 다릅니다.
| 제목 : 챗GPT는 웹의 흐릿한 JPEG (ChatGPT Is a Blurry JPEG of the Web) 부제 : 오픈AI의 챗봇은 의역을 제공하는 반면 구글은 인용문을 제공한다. 어느 것이 더 나은가? (OpenAI’s chatbot offers paraphrases, whereas Google offers quotes. Which do we prefer?) - 파일을 압축하려면 두 단계가 필요하다. 첫 번째는 파일을 더 압축된 형식으로 변환하는 인코딩, 다음은 과정이 반대로 진행되는(압축을 푸는) 디코딩이다. 복원된 파일이 원본과 동일한 경우 압축 과정에서 정보 손실은 없다. 무손실 압축은 텍스트 파일과 컴퓨터 프로그램에 일반적으로 사용되는 방식인데 그 이유는 잘못된 문자 하나라도 재앙이 될 가능성이 있기 때문. - 반대로 복원된 파일이 원본의 100% 같지 않은, 근사치에 가까울 경우 일부 정보가 삭제돼 복구할 수 없다. 이러한 손실 압축은 절대적인 정확도가 크게 중요하지 않은 사진(이미지), 오디오 및 비디오에 자주 사용된다. 저장용량을 줄이기 위해서다. 대부분의 경우 사진, 노래, 동영상은 원본 그대로 완벽하게 재생되지 않는다. 압축을 많이 하기 때문. JPEG(이미지), MPEG(동영상), MP3(음원)은 우리가 많이 사용하는 압축파일들이다. - 복사기도 디지털 압축 방식으로 사용할 경우 이미지가 저하된다. 복사기가 아날로그 방식으로 단순히 흐릿한 출력물을 출력했다면 원본을 정확하게 복사하지 못했다는 사실을 모두가 알겠지만 디지털 방식은 가끔 엉뚱한 숫자를 만들 수도 있다. - 문제는 텍스트가 너무 많이 압축됐기 때문에 정확한 인용문을 검색할 수 없다는 것. 그대로 저장되지 않으니 정확히 일치하는 단어를 얻을 수 없다. - 챗GPT는 웹에 있는 모든 텍스트의 흐릿한 JPEG로 생각해야한다. JPEG가 고해상도 이미지를 유지한다해도 100% 데이터를 줄 수는 없다. 압축 이전의 원본과 다르기 때문. 결국 우리는 근사치에 만족한다. 어쩔 수 없이 ‘흐릿함’이 발생한다. - 이미지 프로그램이 압축 과정에서 손실된 픽셀을 재구성해야 할 때는 주변 픽셀을 보고 평균을 계산하는 것처럼 텍스트도 비슷하다. ‘독립 선언문 스타일을 사용하여 건조기에서 양말을 잃어버렸다고 설명하라’고 질문하면 챗GPT는 어휘 공간에서 두 지점을 가져와 그 사이의 메울 텍스트를 생성한다. 그 결과 “인간사 과정에서 옷의 청결과 질서를 유지하기 위해 옷을 배우자와 분리해야 하는 경우가 있습니다”라는 문장을 만든다. - 챗GPT와 같은 ‘대규모 언어 모델’이 인공 지능의 최첨단이라고 극찬되는 점을 감안할 때 손실이 많은 텍스트 압축 알고리즘 얘기를 꺼내는 것은 딴지거는 것처럼 보일 수 있다. 대규모 언어 모델은 ‘텍스트의 통계적 규칙성(statistical regularities in text)’에 따른다. 텍스트를 정확하게 재구성하지 못한다. 즉 무손실 압축이 아니다. - 챗GPT가 만약 무손실 알고리즘이라면 항상 관련 웹 페이지에서 축약된 인용문을 제공하며 질문에 답할 것이다. 그러면 우리는 아마 이 인공지능을 기존 검색 엔진에 비해 약간 개선된 것으로 간주하고 덜 감동 받을 것이다. 챗GPT는 자료를 그대로 인용하지 않고 다른 말로 표현하기 때문에 마치 자신의 말로 생각을 표현하는 것처럼 보이게 한다. 즉 챗GPT는 자료를 이해한다는 환상을 준다. - 몇 가지 시나리오를 고려해 보자. 대규모 언어 모델이 기존 검색 엔진을 대신할 수 있을까? 확신을 가지려면 이 모델이 선전과 음모론을 무시한다는 전제가 있어야 한다. 그러나 대규모 언어 모델은 우리가 원하는 정보만 포함하더라도, 여전히 흐릿함의 문제가 있다. ‘허용 가능한 흐릿함’의 유형이 있기는 하다. 정보를 다른 단어로 다시 설명하는 것. ‘허용할 수 없는 흐릿함’을 제거하면서 ‘허용 가능한 흐릿함’을 유지하려면 기술적인 발전이 더 있어야 한다. - 아마도 대규모 언어 모델의 흐릿함은 저작권 침해를 피하는 방법으로 유용할 수도 있다(다른 표현으로 설명하니까). 이러한 유형의 재포장이 증가하면 현재 온라인에서 찾고 있는 것을 검색하기 더 어려워진다. 대규모 언어 모델에 의해 생성된 텍스트가 웹에 더 많이 게시될수록 웹은 더욱더 흐릿한 버전이 된다. - 오픈AI는 후속 제품 GPT-4를 개발 중이다. 이 새 인공지능을 학습시키려면 방대한 양의 텍스트가 필요한데, 연구진은 아마도 챗GPT나 다른 대규모 언어 모델에서 생성된 자료를 제외하려고 노력할 것이다. 대규모 언어 모델도 반복되면 손실 압축이 생기기 때문이다(의역). JPEG를 반복해서 다시 저장할 때마다 더 많은 정보가 손실된다. 즉 압축에 의한 왜곡이 계속 생긴다. 복사기를 돌려 반복해 복사하면 화질만 나빠지는 것과 비슷. - 대규모 언어 모델이 원본을 창작하는 데 도움이 될까? 대규모 언어 모델에 의해 생성된 텍스트로 작가가 소설이든 논픽션이든 독창적인 것을 쓰려고 할 때 유용한 출발점이 될 수 있을까? 상용구 같은 것을 대규모 언어 모델에 맡기면 작가가 정말 창의적인 부분에 집중할 수 있을까? - ‘흐릿한 복사본’으로 창작을 시작하는 것은 좋은 방법이 아니다. 당신이 작가라면 독창적인 것을 쓰기 전에 독창적이지 않은 작품(베껴 쓰기 같은)을 많이 쓰기 마련이다. 독창적이지 않은 작업에 들인 시간과 노력은 낭비되지 않는다. 오히려 그것이 궁극적으로 독창적인 것을 창조할 수 있게 해주는 것이다. 올바른 단어를 선택하느라 고심하고, 문장을 재배열하는데 수고를 아끼지 않아야 글쓰기 능력이 향상된다. 학생들에게 에세이를 쓰게 하는 것은 단순히 자료에 대한 이해도를 테스트하는 게 아니다. 자신의 생각을 분명히 표현하는 경험을 주는 것이다. - 대규모 언어 모델로 출력한 글이 인간 작가의 초안과 크게 다르지 않다고 말할 수도 있다. 하지만 이것은 그냥 비슷한 것일 뿐이다. 당신의 초안은 비록 형편없다 해도 독창적인 아이디어이다. |
청계천 옆 사진관 >
구독
![평창군, 발왕산 무장애 나눔길 사업 완료[청계천 옆 사진관]](https://dimg.donga.com/a/180/101/95/2/wps/NEWS/IMAGE/2024/12/26/130728500.1.jpg)
이런 구독물도 추천합니다!
-

고양이 눈
구독
-

횡설수설
구독
-
황형준의 법정모독
구독
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0