공유하기
[리뷰] 국산 반도체의 진면모를 파헤치다, 퓨리오사AI 워보이 NPU
- 동아닷컴
-
입력 2023년 6월 2일 13시 22분
글자크기 설정
이로 인해 반도체 업계는 인공지능 개발에 최적화된 형태의 반도체, 신경망 처리 장치 (Neural Prosessing Unit, 이하 NPU) 개발에 힘을 싣고 있다. 국내에서는 퓨리오사AI와 리벨리온, 사피온 등이 시제품 혹은 상용 제품을 내놓은 상황인데, 가장 주목도가 높은 제품이 지난해 퓨리오사AI가 출시한 NPU ‘워보이’다.

워보이는 이미지 및 비디오 분석, 지능형 교통관리, 초고해상도, 광학 문자인식 및 자율주행 도메인을 위한 인공지능 전용 반도체로, 삼성 파운드리의 14나노 핀펫 공정을 기반으로 제조됐다. 워보이는 최근 과학기술정보통신부가 주관한 AI바우처 등 사업에서 과반 이상의 기업이 선택하는 등 실제 상용화 과정에서도 두각을 나타내고 있다. 퓨리오사AI의 도움을 받아 국산 인공지능 반도체 ‘워보이’의 성능과 현장의 목소리를 들어보았다.
퓨리오사AI ‘워보이’란 어떤 제품인가?

제품 폼팩터는 FHHL(Full-height half-length), HHHL(Half-height half-length) 두 종류로 제공되고, 호스트 인터페이스는 PCIe Gen 4 8레인이다. 열설계전력(TDP)은 구성에 따라 40W에서 60W 사이며, 동작 온도는 0~50도, 방열 구성은 패시브 및 액티브 쿨링 모두 지원한다. 메모리는 32MB가 온칩 메모리(SRAM)로 구성되며, 4266Mbps 동작 속도의 LPDDR4X 메모리가 16GB에서 최대 32GB 구성으로 탑재된다. 최대 메모리 대역폭은 초당 66GB다.

시스템 규모는 일반적인 AI 추론(Inference) 업체를 기준으로 서버 한 대당 워보이 2대, 4대, 8대의 구성을 사용하며, 필요에 따라 최대 20대로 시스템을 구성한 경우도 있다. 특히 동영상 화질 개선 애플리케이션 등의 시스템은 고화질 콘텐츠에 대한 노이즈 저감(Denoising) 성능을 확보하기 위해 서버 한대당 12개의 워보이를 장착한다.
MLPerf로 살펴보는 워보이 NPU의 성능
워보이의 성능은 이미 ML커먼즈(MLCommons)의 인공지능 벤치마크, MLPerf를 통해 증명됐다. MLPerf는 전 세계 스타트업, 선도기업, 학계 및 비영리 단체 등 50개 이상의 창립 멤버와 계열사가 설립한 ‘ML커먼즈(MLCommons)’에서 진행하는 인공지능 성능 시험으로, 현재 전 세계 인공지능 반도체의 성능 지표로 사용된다. 퓨리오사AI는 ML커먼즈의 창립 멤버이며, 2019년 아시아권 스타트업으로는 처음으로 MLPerf에 등재되기도 했다.
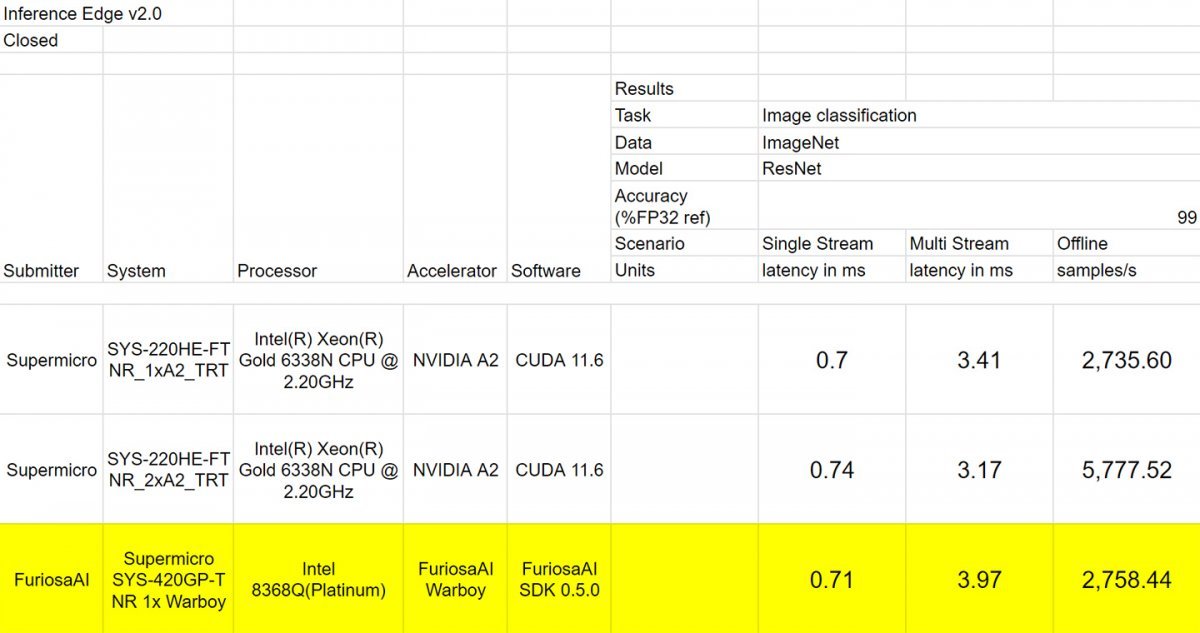
워보이 시스템은 슈퍼마이크로 SYS-420GP-TNR에 인텔 제온 플래티넘 8368Q를 탑재했으며, 비교군으로 엔비디아 A2 한 대에 슈퍼마이크로 SYS-220HE-FTNR, 인텔 제온 골드 6338N을 탑재한 제품이 있다. 이미지 분류 항목에서 워보이의 단일 스트림 레이턴시는 0.71ms, 다중 스트림 반응 시간은 3.97ms로 나타난다. 이때 엔비디아 A2는 각각 0.7ms, 3.41ms로 조금 더 빠르며, 오프라인 시 초당 이미지 처리 수는 2천735.6장이었다. 워보이는 반응 시간은 느렸지만 처리량 자체는 2천758.44장으로 조금 더 빨랐다.
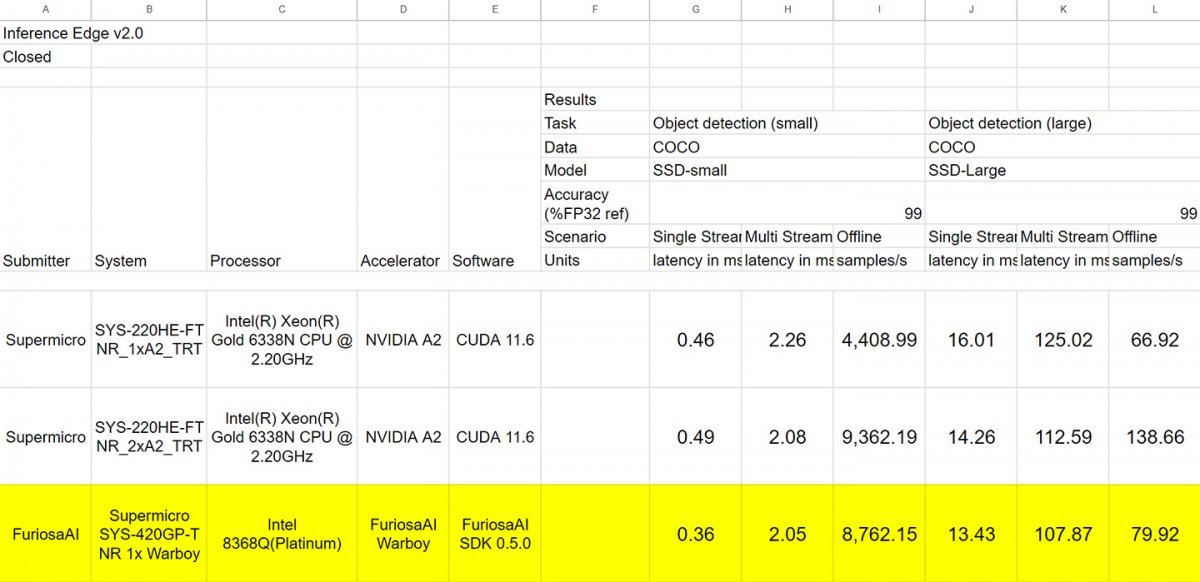
물체 감지(경량) 항목에서는 워보이의 단일 스트림 레이턴시가 0.36ms, 다중 스트림 레이턴시가 2.05ms로 나타났고, 엔비디아 A2가 각각 0.46ms, 2.26ms로 확인됐다. 하지만 실질 처리량은 엔비디아 A2가 4천408.99개일 때 워보이가 8천762.15개로 두 배 가까운 처리량을 보인다. 실제로 동일 시스템에 A2 두 대를 엮은 시스템의 처리량이 9천362.19개니 이미지 처리 효율은 기대 이상이다.
물체감지 (중량) 항목에서도 워보이는 단일 스트림 13.43ms, 다중 스트림 107.87ms으로 초당 79.92개의 데이터를 처리했는데, 이는 단일 16.01ms, 다중 125.02ms로 초당 66.92개를 처리한 엔비디아 A2에 상당히 앞선 수치다.
소프트웨어 개발 키트(SDK) 배포, 실전에서도 활약 중
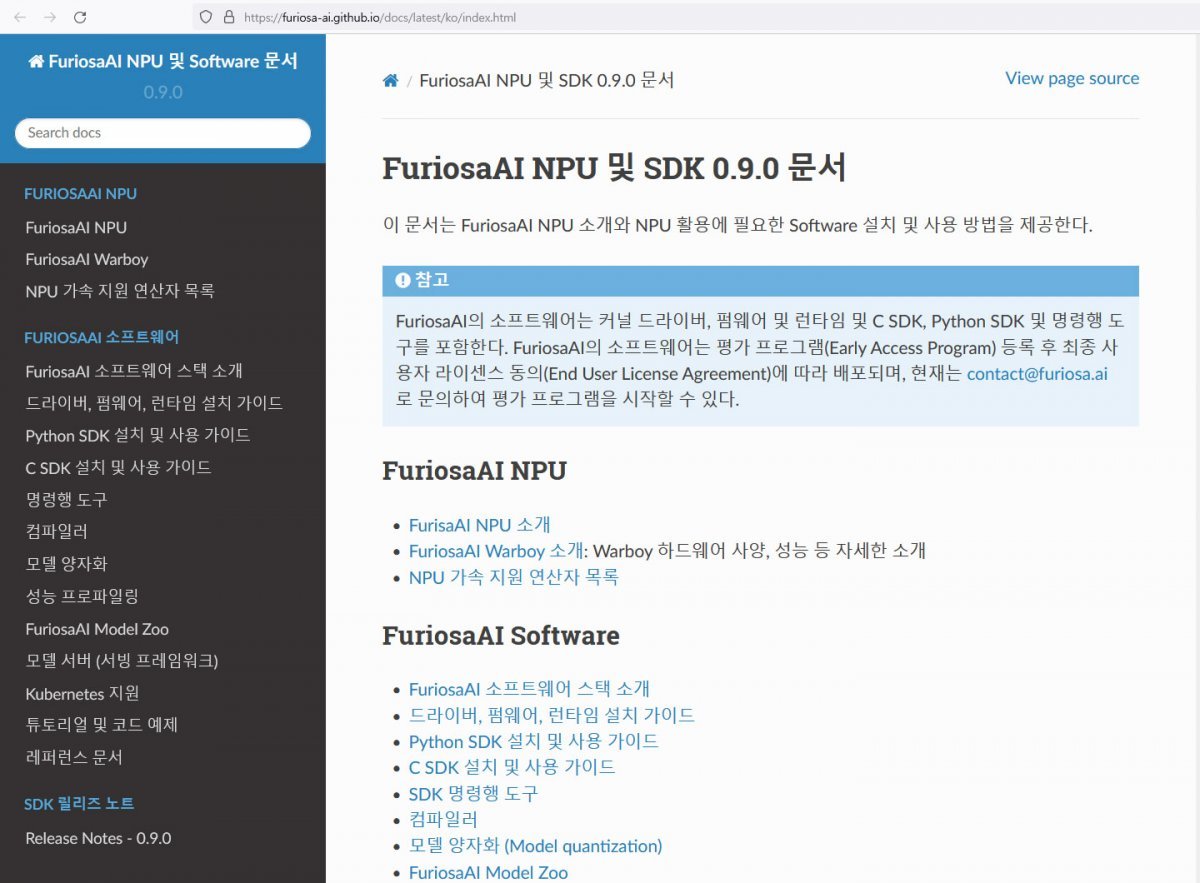
퓨리오사AI 관계자는 “퓨리오사AI는 워보이로 인공지능 서비스를 개발하는 기업들이 필요한 정보를 직접 확인할 수 있게 깃허브에 관련 내용 및 SDK 문서를 공유하고 있다”라면서, “SDK를 제공하고 업데이트하는 이유는 소프트웨어 역량 확보가 인공지능 반도체의 경쟁력을 좌우하는 큰 기준점이라고 생각하기 때문이며, 전 세계 시장 눈높이에 맞는 풀스택 엔지니어링을 수행할 수 있는 근본 개념 설계 역량을 바탕으로 알고리즘, 소프트웨어, 그리고 하드웨어 개발을 수직 통합하는 역량을 갖추고자 노력해 왔기 때문이다”라고 말했다. 또한 “대다수 NPU 제조사들이 우리만큼 자료를 제공하지 못하는데, 이 부분에서 많은 수요 기업들이 자사 기술력을 신뢰하는 듯하다”라고 덧붙였다.
하드웨어 및 소프트웨어를 모두 갖춘 덕분에 이미 상용 서비스에도 도입이 돼있다. 카카오엔터프라이즈는 이팝소프트의 ‘말해보카’ 영어사전 앱에서 광학문자인식(OCR) 기능에 워보이를 활용하고 있다. 영어 문장이 포함된 사진을 촬영하면 앱이 해당 문장을 텍스트화하는데, 이 과정에서 워보이 NPU가 문자를 인식한다. 현재 카카오 i 클라우드는 퓨리오사AI 워보이 NPU 12대가 4개의 베어메탈 서버에 장착돼 있고, 올해 안에 워보이 NPU 카드 16장, 베어메탈 서버 10대를 추가할 계획이다.

AI 스튜디오, 비전 솔루션 등을 개발하는 써로마인드(SURROMIND)는 다중 분류(Multi-class Classification)의 추론 및 클라우드 기반의 음원 추천 시스템에 워보이를 활용할 예정이다. 써로마인드 정헌수 연구원은 “워보이는 우리가 요구하는 결과에 부합하는 하드웨어 성능을 갖추고 있으며, SDK 등 기술 문서도 개발자에게 익숙한 포맷으로 잘 정리해 놨다”라면서, “워보이의 빠른 응답 속도 및 성능 덕분에 맞춤형 음원 목록을 더욱 빠르게 추론해서 반환할 것으로 기대하며, 사업 규모가 커짐에 따라 늘고 있는 추론 요청도 해소할 수 있으리라 본다 ” 라고 활용처를 밝혔다.
근거 있는 자신감, 선택은 시작됐다

시장에서 워보이에 주목하고 있는 이유는 결국 우수한 와트당 성능, 그리고 수급의 안정성과 관련돼 있다. 오늘날 컴퓨터 서버는 대량의 전력을 소모하며 이를 유지하기 위한 자원이 꾸준히 투입돼야 한다. 하지만 RE100 등의 탄소 중립은 물론 EU 공급망 실사처럼 실질적인 소비전력 감축과 그 대안이 요구되는 상황이다. 기업 입장에서 더 나은 성능을 확보하고, 시장의 요구에 발맞추기 위해서라도 장기적으로 GPU를 NPU로 바꿔야 하는 상황이다. 특히 지금처럼 GPU 수요가 폭발해 품귀 현상을 겪는 상황에서는 NPU가 매력적인 대체재로 떠오르는 상황이다.
퓨리오사AI 워보이를 채택한 딥핑소스(Deeping Source) 김태훈 대표의 경우 “워보이를 선택한 가장 큰 이유는 소프트웨어 개발 편의성 때문이다. 엔비디아를 제외하면 툴킷이 직관적이거나 쉬운 기업이 거의 없는데, 퓨리오사AI의 워보이는 바로 당일에 작동 결과를 알 수 있을 정도였다”라고 선택의 이유를 말하며, 래블업(Lablup Inc) 신정규 대표는 “고해상도 이미지 전처리 및 이미지 콘텐츠 인식 등에 관련된 모든 분야, 감시 체계 및 자율주행 데이터 처리 분야에서 워보이의 가능성을 보고 있다. 향후 시각 인식 영역을 넘어 다양한 영역에서 퓨리오사 AI의 NPU가 전개될 것으로 보고 워보이와 통합 작업을 진행하고 있다”라고 말한다.
국내의 여러 NPU 제조사들의 선의의 경쟁을 펼치고 있지만, 유독 퓨리오사AI의 워보이가 앞서나가는 배경엔 이런 현장의 목소리가 있다.
동아닷컴 IT전문 남시현 기자 (sh@itdonga.com)
트렌드뉴스
-
1
이란 공격에 4500억짜리 美 ‘하늘의 눈’ E-3 파괴
-
2
이스라엘 ‘엇박자’ 왜?…美 협상 중에 이란 원전 때렸다
-
3
“이물질 나왔다” 짜장면 21개 환불 요구한 손님…알고 보니
-
4
법정서 ‘강도’ 대면하는 나나 “뭔가 많이 잘못됐다”
-
5
‘공천 내홍’ 국민의힘, 경기지사 유승민 출마 설득 총력전
-
6
30세 연하男과 결혼한 中 55세 사업가, 109억 원 혼수품
-
7
세탁실·화장실 고장으로 철수한 20조 원짜리 항모[횡설수설/장택동]
-
8
[김승련 칼럼]국민의힘, 짠물의 힘 vs 맹물의 힘
-
9
국힘 ‘청년 오디션’ 한다더니…이혁재 “아스팔트 청년도 자산” 논란
-
10
“손에 피 묻혔다”…전쟁이 불붙인 역대 최대 美 ‘노 킹스’ 시위
-
1
李 “국가폭력 범죄자들 훈·포장 박탈은 당연한 조치”
-
2
李 “국가폭력, 공소시효 폐지…나치 전범처럼 영구 책임”
-
3
이정현 “가장 어려운 곳에서 역할”…전남·광주 통합시장 출마 시사
-
4
조국, ‘출퇴근 대중교통 한시 무료화’ 제안…“이번 추경에 넣어야”
-
5
‘공천 내홍’ 국민의힘, 경기지사 유승민 출마 설득 총력전
-
6
법정서 ‘강도’ 대면하는 나나 “뭔가 많이 잘못됐다”
-
7
이란, 호르무즈에 ‘150조 톨게이트’ 만드나…통행료 부과법 추진
-
8
정청래 ‘노무현 정신’ 언급하며 “김부겸, 대구서 꼭 이기고 돌아오라”
-
9
“손에 피 묻혔다”…전쟁이 불붙인 역대 최대 美 ‘노 킹스’ 시위
-
10
김부겸, 내일 출마선언…국회 소통관·대구 2·28공원서 발표
트렌드뉴스
-
1
이란 공격에 4500억짜리 美 ‘하늘의 눈’ E-3 파괴
-
2
이스라엘 ‘엇박자’ 왜?…美 협상 중에 이란 원전 때렸다
-
3
“이물질 나왔다” 짜장면 21개 환불 요구한 손님…알고 보니
-
4
법정서 ‘강도’ 대면하는 나나 “뭔가 많이 잘못됐다”
-
5
‘공천 내홍’ 국민의힘, 경기지사 유승민 출마 설득 총력전
-
6
30세 연하男과 결혼한 中 55세 사업가, 109억 원 혼수품
-
7
세탁실·화장실 고장으로 철수한 20조 원짜리 항모[횡설수설/장택동]
-
8
[김승련 칼럼]국민의힘, 짠물의 힘 vs 맹물의 힘
-
9
국힘 ‘청년 오디션’ 한다더니…이혁재 “아스팔트 청년도 자산” 논란
-
10
“손에 피 묻혔다”…전쟁이 불붙인 역대 최대 美 ‘노 킹스’ 시위
-
1
李 “국가폭력 범죄자들 훈·포장 박탈은 당연한 조치”
-
2
李 “국가폭력, 공소시효 폐지…나치 전범처럼 영구 책임”
-
3
이정현 “가장 어려운 곳에서 역할”…전남·광주 통합시장 출마 시사
-
4
조국, ‘출퇴근 대중교통 한시 무료화’ 제안…“이번 추경에 넣어야”
-
5
‘공천 내홍’ 국민의힘, 경기지사 유승민 출마 설득 총력전
-
6
법정서 ‘강도’ 대면하는 나나 “뭔가 많이 잘못됐다”
-
7
이란, 호르무즈에 ‘150조 톨게이트’ 만드나…통행료 부과법 추진
-
8
정청래 ‘노무현 정신’ 언급하며 “김부겸, 대구서 꼭 이기고 돌아오라”
-
9
“손에 피 묻혔다”…전쟁이 불붙인 역대 최대 美 ‘노 킹스’ 시위
-
10
김부겸, 내일 출마선언…국회 소통관·대구 2·28공원서 발표
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개

![[김승련 칼럼]국민의힘, 짠물의 힘 vs 맹물의 힘](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News2/133535385.1.thumb.jpg)

댓글 0