AMD 최고경영자 리사 수(Lisa Su) 박사가 지난 13일(현지 시각) 열린 ‘AMD 데이터 센터 및 AI 기술 발표 행사(AMD Data Center and AI Technology Premiere)’에서 언급한 말이다. 이 행사에서 AMD는 4세대 에픽(EPYC) 프로로세서에 대한 최신 소식과 함께 생성형 인공지능(Artificial Intelligence, 이하 AI) 개발용 신규 AMD 인스팅트(AMD Instinct) MI300 시리즈 가속기를 선보였다. AMD 역시 생성형 AI를 반도체 시장의 주요 흐름으로 판단하고, 본격적으로 생성형 AI용 반도체를 시장에 내놓는다.
AMD, 생성형 AI 가속기와 개방형 플랫폼으로 도전장

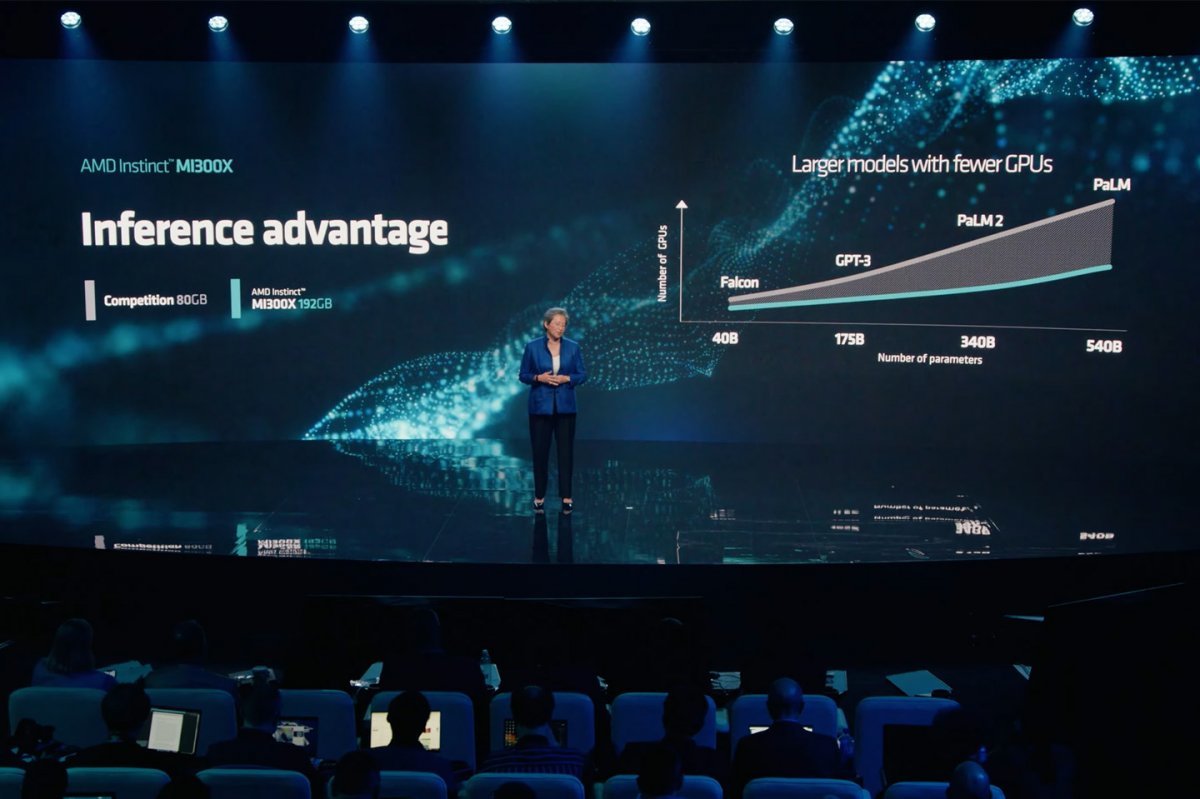
AMD가 발표한 AMD 인스팅트 MI300 시리즈는 AMD CDNA 3 아키텍처 기반의 서버용 반도체로, 생성형 AI 및 고성능 컴퓨팅(HPC)에 특화된 모델이다. 메모리는 최대 192GB의 HBM3 메모리를 지원하며, 대역폭은 초당 5.2 테라바이트다. HBM3(High Bandwidth Memory 3)는 반도체 위에 메모리를 수직으로 쌓아 집적도를 끌어올리는 방식으로, 기존 DDR5 등의 반도체보다 훨씬 크기는 작지만 통신 속도는 월등히 빠르다. 엔비디아 H100과 비교해 HBM 밀도는 약 2.4배 높고, 대역폭은 1.6배 빠르다. 전작인 MI250X과 비교하면 성능은 8배, 효율성은 5배 향상됐다.

AMD 인스팅트 MI300X의 성능은 400억 개의 매개변수로 구성된 팔콘-40과 같은 대형 언어 모델을 단일 가속기로 수용할 수 있다. 행사 중에는 MI300X로 연결된 생성형 AI에 시를 주문하는 시연도 진행됐다. 이외에도 AMD는 데이터 센터 가속기를 위한 ROCm 소프트웨어 생태계 구축을 위한 협력 방안과 AI 구축 플랫폼 허깅페이스에 AMD 인스팅트 가속기, 라이젠 및 에픽 프로세서, 라데온 GPU, 버설, 알베오 등을 비롯한 AMD 제품군을 최적화한다는 내용도 발표했다. AMD 인스팅트 MI300A는 현재 기술 시험 단계인 샘플링 중에 있으며, 고성능 모델인 MI300X는 3분기 중 샘플링에 들어간다.
AMD의 생성형 AI 시장 진출은 사실상 예정된 수순이었지만, 그래도 본격적인 시장 경쟁의 신호탄이라 볼 수 있다. 시장조사기관 IDC에 따르면, 21년 엔비디아의 기업용 GPU 시장 점유율은 91.4%인데 반해 AMD의 점유율은 8.5%에 불과했다. 그럼에도 불구하고 AMD는 시장 2위 사업자며, 엔비디아와 겨룰 수 있는 GPU를 제조하는 몇 안되는 기업 중 하나다.
특히 AMD는 CPU를 직접 제조하는데 따른 호환성의 이점이 있고, 칩렛이나 대역폭 기술 등에 있어서는 엔비디아보다 유리한 측면이 있다. 또한 생성형 AI로 인해 GPU 수요가 폭발하면서 몇 배로 오른 엔비디아 GPU의 대체제로 시장 점유율을 넓힐 수도 있다. AMD는 적절한 진출 시기를 고민해 왔을 뿐이며, 이번 발표가 그 시작점인 셈이다.
엔비디아와 AMD 격돌하는데, 인텔은?

인텔은 2018년부터 GPU 자체 제작을 시작해, 21년부터 소비자용 그래픽 카드를 비롯한 GPU 제품을 내놓고 있다. 다만 서버용 시장에 대응하는 GPU는 이제 막 걸음마를 뗀 상황이다. 인텔은 지난 2021년 인텔 아키텍처 데이에서 Xe-HPC (코드명 폰테 베키오) 라인업의 제품 정보를 공개했으며, 올해 1월에 들어서야 인텔 데이터센터 GPU 맥스 시리즈라는 이름으로 제품을 공개했다. 인텔 데이터센터 GPU 맥스는 47개의 타일을 단일 구성으로 결합한 형태의 GPU로, 최대 128GB의 HBM 메모리와 128개의 Xe 코어로 구성된다.
그런데 이 제품은 데이터 센터 및 고성능 컴퓨팅 제품이어서 현재 생성형 AI 시장 흐름과는 결이 다르다. 이 때문에 인텔은 지난 3월 폰테 베키오의 후속 제품인 코드명 리알토 브리지(Rialto Bridge)의 개발을 중단하고, 2025년에 출시할 예정인 코드명 팔콘 쇼어(Falcon Shore)를 기업용 GPU 라인업으로 전환해서 주력으로 내세운다.

팔콘 쇼어가 기존 폰테 베키오 GPU와 다른 점은 CPU와 외장 GPU가 유연하게 조합되는 모듈식 타일 기반 아키텍처가 적용된다는 점이다. 타일 아키텍처는 필요한 칩셋을 조합해서 만드는 형태의 개념으로, AMD의 칩렛 구성과 비슷한 기술이다. 인텔은 이 기술을 활용해 CPU와 GPU를 결합한 형태의 ‘XPU’를 선보이려 했는데, CPU보다는 GPU쪽에 더 힘을 실어서 AI 반도체 시장에 대응할 것으로 보인다. 이렇게 조합했을 시 맥스 시리즈 GPU는 최대 9.8테라바이트의 총 대역폭을 갖추며, 최대 288GB의 HBM3 메모리를 사용할 수 있다.
결과적으로 인텔이 리알토 브리지를 접고, 2025년을 목표로 팔콘 쇼어를 내놓기로 가닥을 잡으면서 인텔의 전략에도 상당한 차질이 예상된다. 인텔이 팔콘 쇼어를 XPU가 아닌 GPU 형태로 내놓을 것으로 보이는데, 이미 엔비디아는 지난 5월 열린 컴퓨텍스에서 Arm 그레이스 CPU와 호퍼 아키텍처 기반의 GPU를 결합한 ‘GH200 그레이스 호퍼’를 공개한 바 있다.

즉 엔비디아가 팔콘 쇼어와 비슷한 개념을 상품화한 뒤 2~3년이 지나고, AMD가 MI300X 후계 제품을 공개할 시점이 되어서야 지금 전략에 맞춰 수정된 차세대 데이터센터 GPU 맥스 제품군이 등장한다는 의미다. 앞으로의 GPU 시장 경쟁에서 인텔이 어느 정도 선방할지는 당분간 짐작하기 어려울 것으로 보인다.
생성형 AI로 촉발된 반도체 경쟁, 새로운 ‘슈퍼사이클’ 올까?
이렇게 수요가 공급을 상회하면 반도체 업계는 PC 시장 정체로 인해 끊어진 반도체 슈퍼 사이클을 다시 재현할 기회를 얻는다. 슈퍼 사이클은 원자재 등 상품 가격이 10~20년 간 장기간 상승하는 추세를 뜻하는데, 수요가 폭발하면서 공급이 따라가지 못해 가격이 상승할 때 나타나는 현상이다. 현재 반도체 업계는 코로나 19 이후 경기 침체와 PC 수요 부진, 공정 첨예화로 인한 기술 개발의 어려움으로 인해 얼어붙은 상황인데, 인공지능 반도체 수요가 이를 타개할 해법이 될 수 있다.
엔비디아 최고경영자 젠슨 황은 “디지털 격차의 종식을 환영하며, 모든 사람이 컴퓨터로 대화하기만 하면 컴퓨터 프로그래머가 될 수 있는 시대가 올 것”이라고 말했다. 확실히 그의 말대로 인공지능은 우리의 삶을 다시 한번 바꿔놓을 듯하며, 인공지능 반도체 시장은 그 흐름을 타고 성장할 것이다.
동아닷컴 IT전문 남시현 기자 (sh@itdonga.com)
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0