공유하기
오픈AI, 영상 생성 AI '소라' 공개…악용 우려에 '레드팀 검증'부터
- 동아닷컴
-
입력 2024년 2월 16일 18시 46분
글자크기 설정
오픈AI는 15일(현지시각) 홈페이지를 통해 소라를 공개했다. 사용자가 입력한 프롬프트(명령어)에 따라 최대 1분짜리 영상을 만들어 주는 생성형 AI 모델이다.

오픈 AI가 공개한 영상을 보면 ‘세련된 여성이 따뜻하게 빛나는 네온사인과 움직이는 도시 간판으로 가득한 도쿄 거리를 걷고 있다. 그녀는 검은 가죽 자켓, 붉고 긴 드레스, 검은 부츠 차림에 손가방을 들고 있다. 그녀는 선글라스와 빨간 립스틱을 착용하고 있다. 자신감 있고 자연스럽게 걷는다. 길은 축축하고 화려한 조명을 반사하며 거울 같은 효과를 낸다. 많은 보행자가 주위를 걷는다’는 길고 복잡한 프롬프트와 정확히 일치하는 59초 분량 영상이 생성된다.

‘골드러시 시기의 캘리포니아를 담은 역사 기록 영상’이라는 비교적 간소한 프롬프트를 입력해도 그에 맞는 적절한 영상을 생성해준다. 이미지를 영상으로 만들 거나, 기존 영상의 길이를 확장하고, 누락된 장면을 채워 넣는 방식으로도 활용할 수 있다고 오픈AI는 덧붙였다. 기존 영상의 배경을 바꾸거나, 두 영상을 자연스럽게 이어지도록 합치는 등 영상 편집에도 응용할 수 있다.
소라는 달리(DALL·E), 미드저니, 스테이블 디퓨전 등 이미지 생성 AI와 같은 확산 모델(DIffusion Model)을 사용한다고 오픈AI는 소개했다. 확산 모델은 노이즈로 가득한 이미지에서 점차 노이즈를 제거하며 원하는 이미지를 생성하는 방식으로 작동한다. 또한 소라는 거대언어모델(LLM)이 텍스트를 컴퓨터가 이해할 수 있는 단위인 토큰으로 쪼개 처리하듯, 영상과 이미지를 패치(Patch)라는 단위로 쪼개어 처리한다.
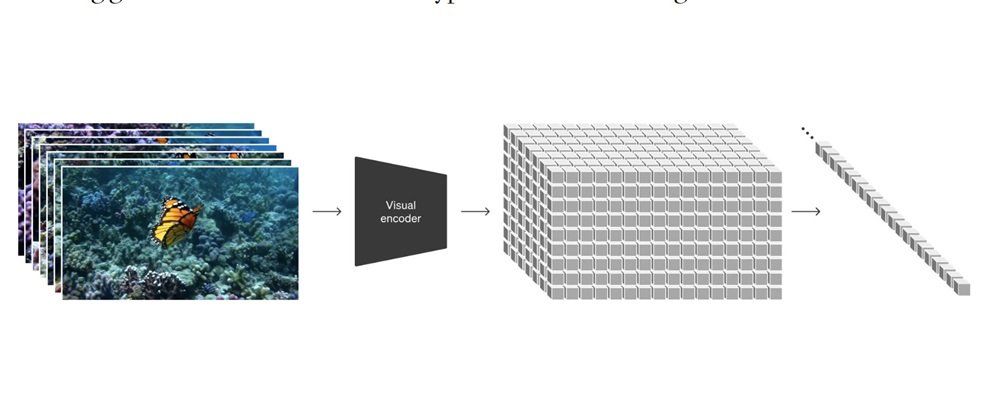

소라는 아직 일반에 공개되지는 않았다. 오픈AI는 이날부터 소라를 ‘레드팀 구성원’이 사용할 수 있게 됐다고 했다. 레드팀 구성원들은 소라의 유해성과 위험성을 평가하는 역할을 하게 된다. 딥페이크와 같은 AI 악용 우려를 미리 차단하려는 의도다.
오픈AI는 동영상 생성 시점, AI 사용 여부 등을 감지할 수 있는 정보를 소라로 생성한 영상에 포함해 악용 소지를 막겠다는 계획이다. 달리3 등 기존 오픈AI 제품에 이미 적용된 안전 조치들 또한 소라에 적용한다. 폭력적이거나 성적인 콘텐츠, 혐오 콘텐츠, 유명인 초상이나 다른 이의 저작권을 침해하는 등 사용 정책을 위반하는 프롬프트를 입력하면 영상 생성을 거부한다.
일부 비주얼 아티스트, 디자이너, 영상 제작자 등 관련 전문가들에게도 사용 권한을 부여하기로 했다. 이들의 의견을 수렴한 뒤 전문적 목적으로 사용할 수 있는 수준까지 모델을 발전시키겠다는 계획이다.
트렌드뉴스
-
1
17년 망명 끝에, 부모 원수 내쫓고 집권[지금, 이 사람]
-
2
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
3
“스페이스X 기대감에 200% 급등”…블룸버그, 한국 증권주 ‘우회 투자’ 부각
-
4
스벅 통입점 건물도 내놨다…하정우, 종로-송파 2채 265억에 판다
-
5
[단독]위기의 K배터리…SK온 ‘희망퇴직-무급휴직’ 전격 시행
-
6
‘李 지지’ 배우 장동직, 국립정동극장 이사장 임명
-
7
美대법 “의회 넘어선 상호관세 위법”…트럼프 통상전략 뿌리째 흔들려
-
8
주한미군 전투기 한밤 서해 출격…中 맞불 대치
-
9
“심장 몸 밖으로 나온 태아 살렸다” 생존 확률 1% 기적
-
10
대미투자 약속한 韓, ‘트럼프 상호관세 위법’으로 불확실성 휩싸여
-
1
“尹 무죄추정 해야”…장동혁, ‘절윤’ 대신 ‘비호’ 나섰다
-
2
“재판소원, 4심제 운영 우려는 잘못… 38년전 도입 반대한 내 의견 틀렸다”
-
3
尹 “계엄은 구국 결단…국민에 좌절·고난 겪게해 깊이 사과”
-
4
한동훈 “장동혁은 ‘尹 숙주’…못 끊어내면 보수 죽는다”
-
5
유시민 “李공소취소 모임, 미친 짓”에 친명계 “선 넘지마라”
-
6
“尹어게인 공멸”에도 장동혁 입장 발표 미뤄… 국힘 내분 격화
-
7
尹 ‘입틀막’ 카이스트서…李, 졸업생과 하이파이브-셀카
-
8
[사설]“12·3은 내란” 세 재판부의 일치된 판결… 더 무슨 말이 필요한가
-
9
[단독]美, 25% 관세 예고 前 ‘LNG터미널’ 투자 요구
-
10
“윗집 베란다에 생선 주렁주렁”…악취 항의했더니 욕설
트렌드뉴스
-
1
17년 망명 끝에, 부모 원수 내쫓고 집권[지금, 이 사람]
-
2
국힘 내부 ‘장동혁 사퇴론’ 부글부글…오세훈 독자 행보 시사도
-
3
“스페이스X 기대감에 200% 급등”…블룸버그, 한국 증권주 ‘우회 투자’ 부각
-
4
스벅 통입점 건물도 내놨다…하정우, 종로-송파 2채 265억에 판다
-
5
[단독]위기의 K배터리…SK온 ‘희망퇴직-무급휴직’ 전격 시행
-
6
‘李 지지’ 배우 장동직, 국립정동극장 이사장 임명
-
7
美대법 “의회 넘어선 상호관세 위법”…트럼프 통상전략 뿌리째 흔들려
-
8
주한미군 전투기 한밤 서해 출격…中 맞불 대치
-
9
“심장 몸 밖으로 나온 태아 살렸다” 생존 확률 1% 기적
-
10
대미투자 약속한 韓, ‘트럼프 상호관세 위법’으로 불확실성 휩싸여
-
1
“尹 무죄추정 해야”…장동혁, ‘절윤’ 대신 ‘비호’ 나섰다
-
2
“재판소원, 4심제 운영 우려는 잘못… 38년전 도입 반대한 내 의견 틀렸다”
-
3
尹 “계엄은 구국 결단…국민에 좌절·고난 겪게해 깊이 사과”
-
4
한동훈 “장동혁은 ‘尹 숙주’…못 끊어내면 보수 죽는다”
-
5
유시민 “李공소취소 모임, 미친 짓”에 친명계 “선 넘지마라”
-
6
“尹어게인 공멸”에도 장동혁 입장 발표 미뤄… 국힘 내분 격화
-
7
尹 ‘입틀막’ 카이스트서…李, 졸업생과 하이파이브-셀카
-
8
[사설]“12·3은 내란” 세 재판부의 일치된 판결… 더 무슨 말이 필요한가
-
9
[단독]美, 25% 관세 예고 前 ‘LNG터미널’ 투자 요구
-
10
“윗집 베란다에 생선 주렁주렁”…악취 항의했더니 욕설
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0