
왜 AMD는 블랙웰이 아닌 호퍼 아키텍처와 비교할까
왜 AMD 인스팅트 MI325X가 호퍼 아키텍처 제품과 비교했는지는 스펙을 통해 알 수 있다. AMD 인스팅트 MI300과 MI325X의 GPU 칩은 동일하다. 아키텍처는 CDNA3 기반이며, TSMC 5nm 및 6nm 핀펫(FinFET) 공정으로 제조됐다. 처리 유닛인 스트림 프로세서도 1만 9456개로 같고, 동작 속도도 2100MHz로 동일하다. 성능은 두 프로세서 모두 FP16이 1.3페타플롭스, FP8이 2.61페타플롭스다.
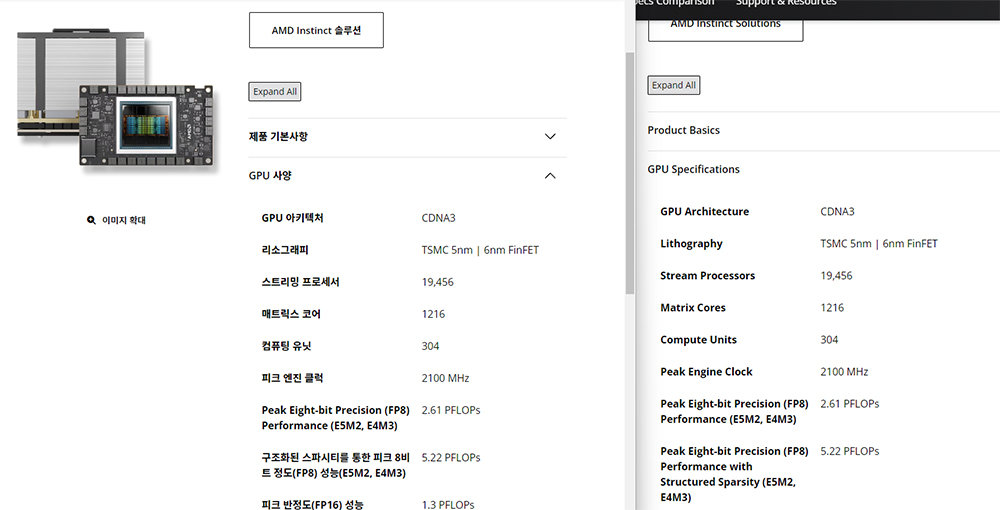
프로세서 및 성능은 동일하되, 메모리만 다르다. MI300X는 192GB HBM3(고대역폭 메모리)를 사용하는 반면, MI325X는 256GB HBM3E를 사용한다. 메모리 속도도 5.2GHz에서 6GHz로 올랐고, 최대 대역폭도 초당 5.3TB에서 최대 6TB로 올랐다. 이에 따라 소비전력은 최대 750W에서 1000W로 상향됐다. 즉 MI300X에서 메모리 성능만 끌어올린 것이 MI325X의 핵심이다.
경쟁 제품으로 지목된 엔비디아 H100은 80GB HBM3, H200은 141GB HBM3E를 탑재하며, 프로세서는 호퍼 아키텍처를 TSMC 4N 공정으로 제조했다. 성능은 두 제품 모두 FP16이 1.5페타플롭스, FP8이 3페타플롭스로 동일하다. 반면 블랙웰은 한 세대 앞선 TSMC N4P 공정을 활용하며, 성능도 FP16이 2.2 페타플롭스, FP8이 4.5페타플롭스로 한층 높을 것으로 예상된다.

계산해 보자면 AMD 인스팅트 MI325X는 MI300X의 메모리 증설 모델이며, 프로세서 변경은 없었다. 엔비디아 H200과 H100도 마찬가지다. 공정 측면에서는 22년 출시된 H100이 오히려 23년 말 출시된 MI300X보다 앞선다. 따라서 MI300 시리즈는 2024년에 제작되는 B200과 경쟁하는 게 아니라 호퍼 아키텍처 기반인 H100과 비교하는 것이 옳다.
엔비디아 블랙웰에 대항하는 제품은 내년 말 출시 예정인 MI325X의 후속 제품인 인스팅트 MI355X다. MI355X는 CDNA4로 아키텍처가 상향되고, TSMC 3nm 공정을 활용할 예정이다. 이러면 AMD 인스팅트 MI355X는 3nm 공정, 엔비디아 역시 이에 근접하는 4NP 공정을 바탕으로 하니 직접적인 경쟁이 가능해진다. 엔비디아는 2026년 블랙웰 다음 세대 제품인 ‘루빈’에 3nm 공정을 채택할 것으로 보인다.
아키텍처 변경 없이 메모리만 증설하는 이유
원리는 일반 사용자용 PC와 비슷하다. 일반 PC에서 처리 성능의 핵심은 CPU가 결정한다. 메모리 용량이 CPU 성능을 직접 높이진 않는다. 4GB 메모리 PC도 64GB 메모리 PC도 CPU가 같으면 CPU의 최대 성능은 동일하다. 하지만 작업에 따라 메모리가 부족해지는 경우 병목 현상이 발생하고, 이로인해 CPU가 데이터에 접근하는 속도가 느려지고, 처리 속도가 느려진다. AMD와 엔비디아 모두 데이터를 더 크고 원활하게 처리하도록 메모리 증설 제품을 출시하는 것이다.
AMD는 AI 종합 인프라 기업, 엔비디아는 AI 가속기 선도 추구

AMD가 이번 행사를 통해 알리고 싶었던 부분은 AMD가 AI 종합 기업을 추구한다는 점이며, 이는 AMD 펜산도 셀리나 400 데이터 처리 장치(DPU) 및 폴라라 400 네트워크 인터페이스 카드(NIC)의 공개로 알 수 있다. 데이터센터의 AI 네트워크는 AI 시스템 및 인프라를 총체적으로 구분하는 ‘AI 클러스터’에 데이터와 정보를 전달하는 프론트엔드, 그리고 AI 가속기와 시스템 간의 데이터 연결을 돕고 관리하는 백엔드로 나뉜다. AMD가 공개한 셀리나 400 DPU는 프론트엔드를 처리하고, 폴라라 400 NIC가 백엔드를 처리한다.
성능 측면에서는 셀리나 400 DPU가 초당 최대 400GB의 데이터를 처리하고, 이전 세대 최대 두 배의 성능을 낸다. 폴라라 400은 최초로 울트라 이더넷 컨소시엄의 기술 표준을 지원하는데, 이를 통해 엔비디아 NV링크를 대체한다. NV링크는 엔비디아가 개발한 GPU 다중 연결 기술로, 많은 GPU가 가속 컴퓨팅으로 쓸 수 있도록 한다. 현재 엔비디아의 GPU가 가장 효율적인 이유가 이 기술인데, 업계에서는 울트라 이더넷 컨소시엄의 UALink로 이를 대체하려 한다.

AMD는 5세대 에픽 프로세서와 인스팅트 MI325X는 물론 데이터 센터에서 쓰는 DPU와 NIC, 이더넷 어댑터, 미디어 가속기는 물론 적응형 시스템온 칩과 FPGA까지 거의 모든 서버용 제품을 내놓고 있다. 최근 인수한 ZT 시스템즈를 더하면 데이터 서버에 필요한 제품부터 설계, 구축, 건축까지 모든 과정을 제공하게 된다. 엔비디아는 GPU와 소프트웨어를 통해 AI 가속기 시장 및 데이터 서버 시장 점유율 선도에 더 초점을 맞춘다.
IT동아 남시현 기자 (sh@itdonga.com)
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개


![[사설]벼랑 끝 석유화학, 구조조정 골든타임 놓치면 재앙](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News/130710476.1.thumb.jpg)
댓글 0